Agile Database Development
Agile Story Points – Scope and Effort Management
26-July-2017
Is agile database development beneficial? Yes. The values and principles of agile methodology are generic, and they aim at reducing process wastes, mis-communication, and risks in software development where human intellectual involvment is high, requirement changes are often, and time to market is aggressive. Synergy in the team, sustainable high productivity, and customer satisfaction are frequent benefits of agile development. All these benefits are desirable to database development as well, because it often involves volatile requirements, and highly human intellectual interactions just like application development.
Can we make database development agile then? Yes. Trivial? No. There are some key differences between database development and application development that call for our attention. Most traditional application development agile practices apply, but some do need minor tweaks.
In reality, most significant applications involve data persistence. However, conventionally, data is persisted centrally for different applications. This is particularly the case in bigger organizations. As a result, database development is often somewhat separated from application development. A typical practice is to have a separate database team. When application developers have database needs, they will forward them to the database developers/DBAs. These latter individuals will then design/develop according to the needs of application developers.
In some smaller organizations, application developers sometimes directly implement changes to the database. In this article, the term application development refers strictly to non-database related development work. The differences between the two will be explored first. Then, the significance of such differences in regards to Agile methodology will be examined. Finally, a proposed ideal database architecture and development process will be given as a framework of reference, which can possibly allow visualization and hence easier adaptation to suit different environments and database designs. This suggested solution is by no means universally applicable.
I. UNIQUE DATABASE DEVELOPMENT CHARACTERISTICS
The following traits are characteristic of database development when compared with application development. Please note that these traits are all inter-related.
- Stateful. The main artifacts of application development code are programming language specific code files, and sometimes configuration files. Business data is often not considered as a product of application development. This is not the case for database development. Business production data is a “living” entity that retains the current state of the business entities. The production data also changes with time. Maintaining the healthy state of such data is definitely part of the deliverables of any database development.
- High Coupling. Applications are usually developed for different business initiatives at different times in an organization. However, most applications share the same fundamental business entities which are mapped to the data. Redundant/duplicated code is bad, and it is worst for data for obvious reasons. Synchronization and security are two of them. So, naturally, having the same database serving multiple applications is common place. The consequence is a central dependency on the database and development work around it.
- Mission Critical. There is probably no error more critical than data loss and data corruption. So quality control will have to be even more stringent than say, GUI design in most cases. This implies defined processes in place to guard against improper modifications to the database.
- Security. Business data can contain personal privacy information, as well as corporate secrets. From the security principle of minimal access, database artifacts are accessible by only a small number of individuals.
- Size. Databases grow in size with time most of the cases. Performance tuning, deployment, backup, and testing are some of the issues that get harder to execute with size. When it comes to the point of doing master slave, or views, or temporary tables, things get complicated.
- Intrinsic Meaning. A lot of applications are driven by the content of the data. If the database is not 1NF normalized, the situation can be more hairy. On the other hand, when and how this data is changed is also very significant. Unfortunately, most organizations do not have good means to document by text or by integrated regression test script to preserve the data life cycle across applications sharing the same database.
- Testability. As a database gains size, it loses testability as well. A database table with tens of thousands of rows and a dozen columns make testing manually too costly, and too time consuming. The accuracy of manual testing is also diminished due to human errors. Typical database testing strategies are extreme cases, manual sampling, and aggregate examination. However, the temporal nature of data states makes coverage hard to determine, especially when there are multiple applications depending on the data.
- SDLC Flow. As a result of the above traits, DBAs and/or database developers are often the final gate keeper of database activities. Staging, migration, and conversion are often part of the SDLC, which are not part of non-database application development.
- Longevity. Application comes and goes. Newer ones replace older ones. Not the case for data. Data might get migrated/converted, but they stay. As time goes, the history of the database gets richer, and development/maintenance grows more complicated, especially if the design and process are not done properly.
II. AGILE VALUES AND DATABASE DEVELOPMENT
- Individuals and interactions over processes and tools. Because of the multi-application coupled nature of database, the database team usually serves many projects concurrently. Some sort of process will need to be in place to orchestrate these changes. However, emphasizing individuals and interactions is not in anyway in conflict with having some processes or tools in place. It is a matter of emphasis, and mentality.
- Working software over comprehensive documentation. Because of intrinsic meaning and testability traits of database development, working software is harder to define. But it is possible as will be pointed out by the suggested ideal database design and process later. To help with communication, documentation on data shared among applications can be documented. At least a documentation map pointing to test scripts (if the test scripts comprehensively describe the functionality of the database objects) should be maintained.
- Customer collaboration over contract negotiation. Since most database development deal with application development teams directly instead of the customers, the customers now become the application developers, while the contract will be the design specification. Since database development indirectly, and sometimes directly, fulfill customers’ interests, this Agile value should still be pursued. How? The ideal database development process will illustrate some feasible approaches.
- Responding to change over following a plan. The nature of typical/traditional database development clearly makes it harder to respond to change because the ramification can impact many facets of the organization, from applications, projects, to departments. Again, I hope the ideal database design and process can address this.
III. AGILE PRINCIPLES AND DATABASE DEVELOPMENT
- Our highest priority is to satisfy the customer through early and continuous delivery of valuable software. This can be difficult because the same database can serve multiple applications. However, there are ways to mitigate this as will be explained later.
- Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage. This can be difficult because the same database can serve multiple applications. However, there are ways to mitigate this as will be explained later.
- Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale. This can get more difficult as the number of dependent projects on the same database increases.
- Business people and developers must work together daily throughout the project. Since database developers are sometimes shielded by application developers when it comes to communication with business people, This might not be very applicable. However, communication should still be encouraged to understand the business reasons behind the data requirements.
- Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done. No conflict.
- The most efficient and effective method of conveying information to and within a development team is face-to-face conversation. There can be face-to-face conversation, however, with a single DBA/database developer team supporting multiple application, the amount of time for face-to-face conversation will be limited.
- Working software is the primary measure of progress. Since the data is stateful with a history, it is difficult to say whether a database is working using the conventional database development and management.
- Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely. No conflict.
- Continuous attention to technical excellence and good design enhances agility. No conflict.
- Simplicity–the art of maximizing the amount of work not done–is essential. No conflict.
- The best architectures, requirements, and designs emerge from self-organizing teams. No conflict.
- At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly. No conflict.
IV. SOME AGILE PRACTICES AND DATABASE DEVELOPMENT
- Pairing. No conflict. Pairing can still be very advantageous be it DBA/DBA, DBA/application developer, DBA/BA, DBA/QA.
- Integration Early and Often. Often and Early are relative terms. These should still be emphasized even though an iteration in database development might be longer than that of application development. However, this is not cast in stone.
- Test Driven Development. This can still be done. And it is even more important since multiple applications are dependent on the integrity of the database.
- Short Release Cycles. Short is also a relative term. Cycles should be as short as possible.
- Story Based Process. This is also desirable, however, dependencies must be identified early.
- JIT Design. This is also applicable because requirements from different applications increase the volatility exponentially. It will be even harder to predict good design. Design incrementally will be a better option. Simpler design will also aid refactoring later on if called for.
- Co-location. This can be difficult because the same DBA/database developer can potentially work on multiple projects. But this is not a problem that cannot be fixed.
- Refactoring. Due to the coupling and critical nature, the cost of refactoring will be higher. So, automation will be called for to reduce the impact. The book “Refactoring Databases” by Scott Ambler and Pramod Sadalage talks about categories of database refactoring, and good practices that help with the process.
V. A SOLUTION
There are two objectives in enabling agile database development in an organization. The first one is to make database development agile itself. The second objective is to make database development more supportive of agile application development. The first objective is not a pre-requisite of the second. The two can co-exist as well. Its a matter of the particular situation in the organization.
ARCHITECTURE:
Here is a proposed database architecture (see diagram) that will enable both objectives to be met:
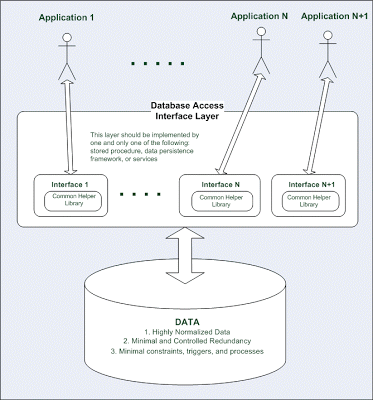
1. Encapsulated Database Interface Access Only.
External access to the data can be done via either stored procedure, persistence frameworks, or web services only. Not only is this more secure. Similar to interface patterns, and SOA, this layer of abstraction allows changes of internal structures without breaking existing contracts to external dependent systems. In other words, informational and behavioral semantics should be cleanly delineated. stored procedures, persistent frameworks, and web services can be used. However, only stick with one. This will mitigate the coupling of having multiple applications accessing the same database since it will be easier to locate and hence control the dependencies. It will also be easier to refactor.
2. Testable Operations Only.
Data should be operated or accessed via only testable means. If a test case/script cannot or does not exist for a DML, query, or access interface, then such access should not be permitted. This will ensure regression coverage to support shorter and iterative development cycles. Analogous to this will be test driven development in application development. It will also make automated regression testing possible.
3. Centralized Logic Layer.
Only the encapsulated layer should be responsible for cascading changes, or making any side effects for any operations. This separation of database access logic and database. Such locality will also make dependencies analysis manageable. Without such measure, one database developer will not be able to find out if his/her work will impact other applications easily.
For mission critical referential integrity, triggers or constraints can be applied as a redundant check in case the encapsulating layer has missed the checking. However, this should be minimized and conventionalized. This will improve visibility across multiple teams in case there are multiple external dependencies to the database.
On the other hand, let’s say stored procedures are used for implementing this layer. The database team can benefit readily from existing good agile application development practices, because developing stored procedures is just like developing other application languages.
4. Traceability/Recoverability.
No hard delete (when size becomes an issue then rotating to tapes or a secondary database will be an option). Audit trail for all DMLs. Backup all data loss due to DDL related changes. Version control of all artifacts, database code, access interface code, DLL, DML, scripts, and even data itself will be required. Obviously, in the case of data, it might not be realistic to backup and version label too frequently. An optimal frequency will need to be figured out. Data will need to be handled more discretely, because it is much harder to guarantee state recovery. From ground up, a database state should be recoverable to any point in time.
5. Normalization.
Peformance optimization should not be done via breaking normalization. Creation of extra views, or temporary tables should be used. These view or temporary tables should be read only. Buffer tables can be used too but the states should be centrally recorded in a normalized table. If there is no choice but to break normalization to fulfill performance requirement, then a central scheme of such approach will be needed across all applications.
6. Strict Convention.
With convention, less documentation, and less mis-understanding. Convenstion should be enforced with automated test scripts, which should ideally be invoked automatically during check-ins. In other words, version control tied with integration system will facilitate enforcement of convention preservation. Certainly, it might not be possible or efficient to always do this, but attempting such either automatically, or manually through defined workflow should be encouraged.
7. Impact Analysis Facilitation.
The database code should be designed with good convention and structure so that impact can be easily analyzed and visualized. This should be taken into account as a design goal. There are also tools to identify side effects or database objects affected. For example, some stored procedure IDE tool can determine what tables are touched by a stored procedure with the click of a button.
DEVELOPMENT PROCESS
1. Scheduled Pull Requests.
External users of the data should pull their demands at defined time. This will help synchronization, and hence traceability. The intervals between pulls should be minimized as much as possible so that rapid response to changes can be obtained.
2. Small Steps.
This makes it easier to trace, recover, and minimize damage. This applies within the database team.
3. Full Regression.
Analogous to frequent integration, full regression test essentially achieve the same purpose, albeit less ideal, as long as all the rules here are followed. It is an alternative to the end-to-end integration in application development. More precisely, database full regression involves testing of all database interfaces including those from other applications. As number of applications dependent on the same database increases,
4. Test Automation.
In order for fast response to changes and quick turnaround to support short release cycles of agile application development, test needs to be automated, especially with the highly coupled nature of database. This will reduce the overhead of manual testing, and errors from human mistakes.
5. Iteration Size.
The architecture and process suggested here support quicker turnaround. Ideally, database development iteration should be much shorter than that of application development so that database development will not be a bottleneck to application development. Otherwise, end to end production ready releases will not be ready unless the database work is done. However, the highly couple, critical, and many other traits of database development can make it difficult to achieve quick turnaround.
Alternatively, during application development iteration planning, database needs, can be looked ahead one iteration. For example, during iteration i planning, database needs for iteration i+1 will be looked at already. Doing it this will will allow database development iteration to be of the same length as that of application development. Of course, this might result in a synchronization of iteration among different applications depending on the same database. In a sense, it is like the CPU clock inside the microprocessor.
6. Flow.
So far, we have talked bits and pieces of processes, and practices. One approach, if economically feasible, is to have a DBA/database developer directly assigned to an application project, and at the same time keeping communication with the rest of the database team from other projects for cross-application impact resolution.
A more realistic approach will be explained below. The following diagram (TBD) might be helpful. Essentially, database development will be done in iterations. During each iteration, applications from different projects will send their requests for database work to the database team. The database team will then examine the requests for their impacts. If an impact is localized to the requesting application only, and the bandwidth allows fulfillment of the request, then it can be done within the iteration. Otherwise, if either the impact is cross-application, or the effort is large, then such request story will be analyzed and prioritized with other request stories. Application team representative, preferrably include the business, should get involved in prioritizing the stories together during database development iteration planning.
Obviously, if the database team continuously become the bottleneck for other application development teams, then resource increase will be justifiable. Another option will then be having separate database schemas. But the problems of master data management, synchronization, reconciliation, etc., will arise.
Application development team should be aware of the potential of database work delivery delay, one iteration lookahead should be considered to minimize impact. If the database is architected properly, then such instances should be minimal.
7. Roles and Responsibilities.
While the architecture and process suggested so far delineate the database team as the sole implementor of the interface access layer. However, this is not a requirement. As a matter of fact, for data intensive applications, it might be better for either the application development team to directly implement this layer, or the database team to assign someone to be devoted to the project working directly with the application team. Of course, whoever works in this layer should have good understanding of database development practices. Moreover, if some core database objects affected is/will be depended by other applications, for example the common helper library or some shared tables, then the database team must be involved as they are the final gate keepers and maintainers of the database.
The layer I am proposing here is more like onion layers. The closer to the core, the more central the control should be. In other words, it is a matter of how we layer the onion. An optimal solution will maximize both turnaround time and data wholesomeness. I have deliberately used “wholesomeness” instead of “integrity” because the latter seems to imply only correctness. For “wholesomeness”, I am also referring to a state of the database that future access, and manipulation of the data are not hampered. For example, if a modification of the database makes it difficult or inefficient to retreive certain reports, then the “wholesomeness” of the database is affected.